- 2085
- 0
- 分享
- 2022-10-12 15:00
目录
1.数据集
1.1.获取数据集
1.2.划分数据集
2.训练
2.1.数据集预处理
2.2.定义模型和优化器
2.3.训练模型
3.测试模型
4.识别垃圾
4.1.MV-EB435i立体相机获取图片
4.2.使模型应用于识别参考文章:Pytorch 深度学习实战教程(五):今天,你垃圾分类了吗?
1.1.获取数据集
在我们平时的要进行深度学习的时候,想要方便获取数据集可以在kaggle平台,ai studio,极市平台,阿里云天池等平台中寻找免费的数据集,在我们当前项目中,要寻找垃圾分类的数据集,在ai studio中有一个种类繁多,数量也多的数据集:垃圾图片库.tar,垃圾数据集有4个大类:可回收垃圾,有害垃圾,其他垃圾,厨余垃圾,数据集有214个小类,57000多张图片,内存有7G多。
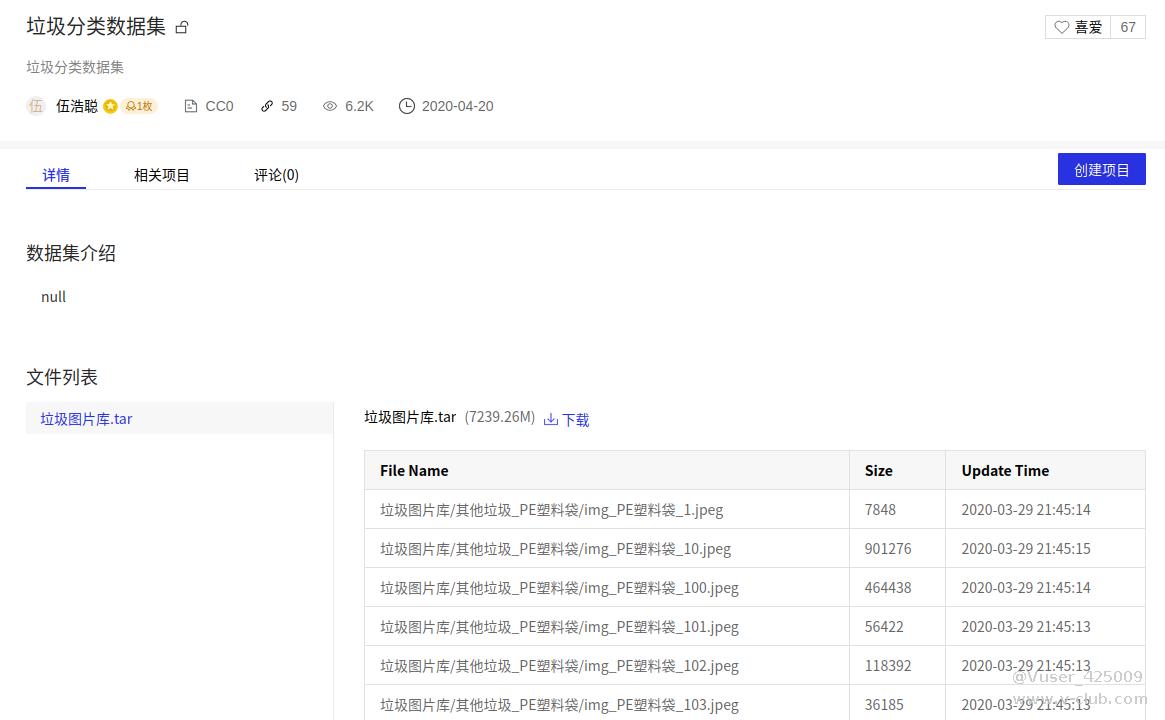
1.2.划分数据集

我们下载的数据集是没有划分训练集和测试集的,需要我们手动划分,我决定按4:1的比例划分成训练集和测试集,我们创建一个file.py文件,代码如下:
import os
path='./test库'
dir1=[]
def file_name(file_dir):
a=0
for root, dirs, files in os.walk(file_dir):
if a==0:
a=1
if os.path.exists(path)==True:
print(1)
for i in dirs:
os.mkdir(path+"/"+i)
else:
break
file_name("./垃圾图片库")
def move_picture():
target_path='./垃圾图片库/'
all_content=os.listdir(target_path)
print('All content numbers is',len(all_content))
list=[]
count_num=1
for content in all_content:
if os.path.isdir(target_path+content):
all_sub_content=os.listdir(target_path+content)
list.append(len(all_sub_content))
print(list)#图片数量
for i in range(214):
list[i]=1/list[i]
print(list)#数量倒数
move_picture() 因为我们的数据集每一个的种类数量是不均匀的,有的种类图片有几百张,而有的种类图片只有几十张,这必然和造成模型学习到的有偏差,所以我们需要知道每一种类的图片数量,获取其倒数,为上面第二次打印的list,其倒数相当于损失函数对每一种类的权重,种类图片数量越多,权重越小,种类图片越少,权重越大,防止图片数量少的种类准确率较低。
2.1.数据集预处理
为对数据集进行归一化,我们需要知道他们的均值和方差,创建一个std_mean.py文件,代码如下:
from torchvision.transforms import ToTensor,Compose,Normalize,Resize#用于把图片转化为张量
import numpy as np#用于将张量转化为数组,进行除法
from torchvision.datasets import ImageFolder#用于导入图片数据集
means = [0,0,0]
std = [0,0,0]#初始化均值和方差
# transform=ToTensor()#可将图片类型转化为张量,并把0~255的像素值缩小到0~1之间
transform =Compose([Resize([224,224]),ToTensor()])
dataset=ImageFolder("./test库/",transform=transform)#导入数据集的图片,并且转化为张量
num_imgs=len(dataset)#获取数据集的图片数量
for img,a in dataset:#遍历数据集的张量和标签
for i in range(3):#遍历图片的RGB三通道
# 计算每一个通道的均值和标准差
means[i] += img[i, :, :].mean()
std[i] += img[i, :, :].std()
mean=np.array(means)/num_imgs
std=np.array(std)/num_imgs#要使数据集归一化,均值和方差需除以总图片数量
print(mean,std)#打印出结果 现在,我们开始正式训练,我们创建一个train.py准备训练模型。
导入相关库和数据集预处理:
import torch#pytorch的库
import torchvision.transforms as transforms
from torch.utils.data import DataLoader#可将多组数据合成一批次
import matplotlib.pyplot as plt#用于画图
import torch.nn as nn#用于构造网络模型
import torch.nn.functional as F#用于构造网络模型
import torch.optim as optim#调用优化器
import numpy as np#用于求数据的均值和方差
import time#用于记录训练所用的时间
from torchvision.datasets import ImageFolder#用于导入数据
from torchvision import models
from tensorboardX import SummaryWriter
from PIL import ImageFile
import os ImageFile.LOAD_TRUNCATED_IMAGES = True#防止导入数据集时错误而报错
train_tf = transforms.Compose([
transforms.Resize([224,224]),
transforms.RandomHorizontalFlip(),#随机图片水平翻转
transforms.RandomVerticalFlip(),#图片随机裁剪
transforms.ToTensor(),
transforms.Normalize((0.6477895, 0.6004517, 0.5478299),(0.21435872, 0.2223378, 0.23691148))
])
val_tf = transforms.Compose([
transforms.Resize([224,224]),
transforms.ToTensor(),
transforms.Normalize((0.6477895, 0.6004517, 0.5478299),(0.21435872, 0.2223378, 0.23691148))
])
train_loader=ImageFolder("./垃圾图片库/",transform=train_tf)
test_loader=ImageFolder("./test库/",transform=val_tf)
train_batch_size=32
test_batch_size=32
n_epochs =80#训练迭代次数
train_loader=DataLoader(train_loader,batch_size=train_batch_size,shuffle=True,num_workers=4)
test_loader=DataLoader(test_loader,test_batch_size)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")#设定在gpu设备上训练
print(device)我用的模型是resnet50,大家可以根据自己的需求来修改
2.2.定义模型和优化器
list=[0.0038910505836575876, 0.0030120481927710845, 0.004464285714285714, 0.0031446540880503146, 0.009259259259259259, 0.005235602094240838, 0.015625, 0.05, 0.005434782608695652, 0.0045045045045045045, 0.001834862385321101, 0.0035587188612099642, 0.011764705882352941, 0.05, 0.004524886877828055, 0.02127659574468085, 0.007936507936507936, 0.008064516129032258, 0.004424778761061947, 0.0038910505836575876, 0.005, 0.004694835680751174, 0.008, 0.004016064257028112, 0.017241379310344827, 0.0051813471502590676, 0.0041841004184100415, 0.009259259259259259, 0.010526315789473684, 0.000846740050804403, 0.002242152466367713, 0.0009930486593843098, 0.021739130434782608, 0.005434782608695652, 0.005128205128205128, 0.006802721088435374, 0.03125, 0.0037313432835820895, 0.005494505494505495, 0.002331002331002331, 0.011904761904761904, 0.004807692307692308, 0.010101010101010102, 0.006172839506172839, 0.0017605633802816902, 0.0037735849056603774, 0.09090909090909091, 0.002173913043478261, 0.0024330900243309003, 0.020833333333333332, 0.008130081300813009, 0.00546448087431694, 0.006756756756756757, 0.025, 0.0047169811320754715, 0.0041841004184100415, 0.009615384615384616, 0.013333333333333334, 0.004219409282700422, 0.004166666666666667, 0.003968253968253968, 0.037037037037037035, 0.008849557522123894, 0.004366812227074236, 0.0045045045045045045, 0.011494252873563218, 0.05555555555555555, 0.05, 0.008620689655172414, 0.015873015873015872, 0.0072992700729927005, 0.001697792869269949, 0.004484304932735426, 0.02702702702702703, 0.007042253521126761, 0.004464285714285714, 0.006622516556291391, 0.0017953321364452424, 0.00423728813559322, 0.0035587188612099642, 0.009615384615384616, 0.00398406374501992, 0.015151515151515152, 0.005235602094240838, 0.015384615384615385, 0.0017889087656529517, 0.00234192037470726, 0.0033783783783783786, 0.005434782608695652, 0.027777777777777776, 0.0020920502092050207, 0.003436426116838488, 0.015151515151515152, 0.015873015873015872, 0.005555555555555556, 0.0035971223021582736, 0.010416666666666666, 0.0023584905660377358, 0.0015527950310559005, 0.005376344086021506, 0.0021929824561403508, 0.004219409282700422, 0.0033444816053511705, 0.0031847133757961785, 0.007246376811594203, 0.0019120458891013384, 0.005, 0.003663003663003663, 0.014492753623188406, 0.002638522427440633, 0.015151515151515152, 0.05263157894736842, 0.003937007874015748, 0.0029411764705882353, 0.0037313432835820895, 0.0038461538461538464, 0.0045045045045045045, 0.0136986301369863, 0.037037037037037035, 0.0040650406504065045, 0.019230769230769232, 0.002457002457002457, 0.0035714285714285713, 0.009523809523809525, 0.007575757575757576, 0.003816793893129771, 0.02, 0.00909090909090909, 0.0022935779816513763, 0.01694915254237288, 0.0012077294685990338, 0.025, 0.004694835680751174, 0.0125, 0.003861003861003861, 0.017241379310344827, 0.001937984496124031, 0.0036363636363636364, 0.004807692307692308, 0.005847953216374269, 0.004629629629629629, 0.004219409282700422, 0.005780346820809248, 0.0033444816053511705, 0.00392156862745098, 0.0035211267605633804, 0.0136986301369863, 0.010869565217391304, 0.004739336492890996, 0.0037174721189591076, 0.030303030303030304, 0.003367003367003367, 0.00390625, 0.025, 0.003968253968253968, 0.004032258064516129, 0.004484304932735426, 0.0038461538461538464, 0.006097560975609756, 0.011494252873563218, 0.00546448087431694, 0.011363636363636364, 0.0016778523489932886, 0.0035087719298245615, 0.003745318352059925, 0.003787878787878788, 0.01639344262295082, 0.013157894736842105, 0.004878048780487805, 0.004166666666666667, 0.008695652173913044, 0.02040816326530612, 0.008130081300813009, 0.004629629629629629, 0.010869565217391304, 0.004629629629629629, 0.005208333333333333, 0.0125, 0.0036231884057971015, 0.017857142857142856, 0.02857142857142857, 0.004878048780487805, 0.0035460992907801418, 0.00909090909090909, 0.010309278350515464, 0.009009009009009009, 0.003676470588235294, 0.008064516129032258, 0.002232142857142857, 0.00392156862745098, 0.005988023952095809, 0.004464285714285714, 0.008849557522123894, 0.003257328990228013, 0.017241379310344827, 0.0038910505836575876, 0.008333333333333333, 0.01098901098901099, 0.027777777777777776, 0.004901960784313725, 0.004032258064516129, 0.07142857142857142, 0.0037313432835820895, 0.0011325028312570782, 0.010869565217391304, 0.004132231404958678, 0.0026041666666666665, 0.0070921985815602835, 0.0037735849056603774, 0.01639344262295082, 0.008620689655172414, 0.0007552870090634441, 0.008130081300813009, 0.02564102564102564]<br/>#这是之前获得的倒数<br/> random_seed = 1
torch.manual_seed(random_seed)#设定随机种子
model = models.resnet50(pretrained=True)#加载预训练模型
fc_inputs = model.fc.in_features
model.fc = nn.Linear(fc_inputs, 214)#设置最后输出类别总数
model = model.cuda()#把模型放在gpu里训练
lr_init = 0.001#学习率
weight_decay = 0.001#衰减率
optimizer = optim.Adam(model.parameters(), lr=lr_init, weight_decay=weight_decay)
scheduler=torch.optim.lr_scheduler.CosineAnnealingLR(optimizer,T_max=32)#用余玄退火控制学习率
2.3.训练模型
def train(epoch): model.train() # 定义网络为训练状态 correct = 0 for batch_idx, (data, target) in enumerate(train_loader): # 遍历数据集 data, target = data.to(device), target.to(device) # 将数据集转移到gpu上训练 optimizer.zero_grad() # 把梯度清零 output = model(data) # 前向传播获取输出结果 criterion = nn.CrossEntropyLoss( weight=torch.from_numpy(np.array(list)).float(), size_average=True).cuda() ### 要想使用GPU,此处必须使用cuda() criterion.cuda() loss = criterion(output, target) loss.backward() # 反向计算求取梯度,更新参数 optimizer.step() # 更新优化器 scheduler.step() # 更新学习率 pred = output.data.max(1, keepdim=True)[1] # 获取每一行的输出最大值的索引,即第1个元素为具体值,第二个元素为其索引 correct += (pred.eq(target.data.view_as(pred)).sum()).cpu() # 计算预测的正确个数,注意,要当前数据在gpu,需转移到cpu才能添加到列表 print('lr:{}\tTrain Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f},Accuracy: {}/{} ({:.3f}%)\n'.format(optimizer.state_dict()["param_groups"][0]["lr"], epoch, batch_idx * (len(data)+1), len(train_loader.dataset), 100. * batch_idx * len(data)/ len(train_loader.dataset), loss.item(), correct, len(train_loader.dataset), 100. * correct / len(train_loader.dataset))) # 打印进度,loss和准确率 torch.save(model.state_dict(), './model/model_garbage.pth') # 保存模型 torch.save(optimizer.state_dict(), './model/optimizer_garbage.pth') # 保存优化器 try: if os.path.exists("./model/model_garbage.pth"): # 判断模型是否存在 model.load_state_dict(torch.load("./model/model_garbage.pth")) # 导入模型 optimizer.load_state_dict(torch.load("./model/optimizer_garbage.pth")) print("loading successfully!") finally: t_1=time.time() for i in range(1,n_epochs):#训练n_epochs次 train(i) t_2=time.time() t=t_2-t_1 print("所用时间:",t)#记录训练所用时间
test()#测试 if __name__=="__main__": run()
3.测试模型
创建val.py文件,代码如下:
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
from torchvision import models
import torch.nn as nn
import torch
import os
import numpy as np
import matplotlib.pyplot as plt
from torchvision.datasets import ImageFolder#用于导入数据
import torch.nn.functional as F#用于构造网络模型
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
val_tf = transforms.Compose([
transforms.Resize([224,224]),
transforms.ToTensor(),
])
with open('dir_label.txt', 'r', encoding='utf-8') as f:
labels = f.readlines()
labels = list(map(lambda x: x.strip().split('\t'), labels))
if __name__ == "__main__":
test_loader = ImageFolder("./test库/", transform=val_tf)
test_loader = DataLoader(dataset=test_loader, num_workers=1, pin_memory=True, batch_size=1)
model = models.resnet50(pretrained=False)
fc_inputs = model.fc.in_features
model.fc = nn.Linear(fc_inputs, 214)
model = model.cuda()
# 加载训练好的模型
checkpoint = torch.load('model_best_checkpoint_resnet50.pth.tar')
model.load_state_dict(checkpoint['state_dict'])
model.eval()
arr=[]
total=[]
arr1=[]
for _ in range(214):
arr.append(0)
total.append(1)
arr1.append(0)
for i, (image, label) in enumerate(test_loader):
src = image.numpy()
src = src.reshape(3, 224, 224)
src = np.transpose(src, (1, 2, 0))
image = image.cuda()
pred = model(image)
pred = pred.data.cpu().numpy()[0]
score = F.softmax(pred)
pred_id = np.argmax(score)
print(i)
if label == pred_id:
arr[label] += 1
total[label] += 1
for i in range(214):
arr1[i]=arr[i]/total[i]*100
print(arr1)
输出结果如下,为每一个种类的预测准确率:

我总结了模型的性能在最下面附件的doc里面,因为内容太多我就不展示了,大家可以点开查看。
4.识别垃圾
4.1.MV-EB435i立体相机获取图片
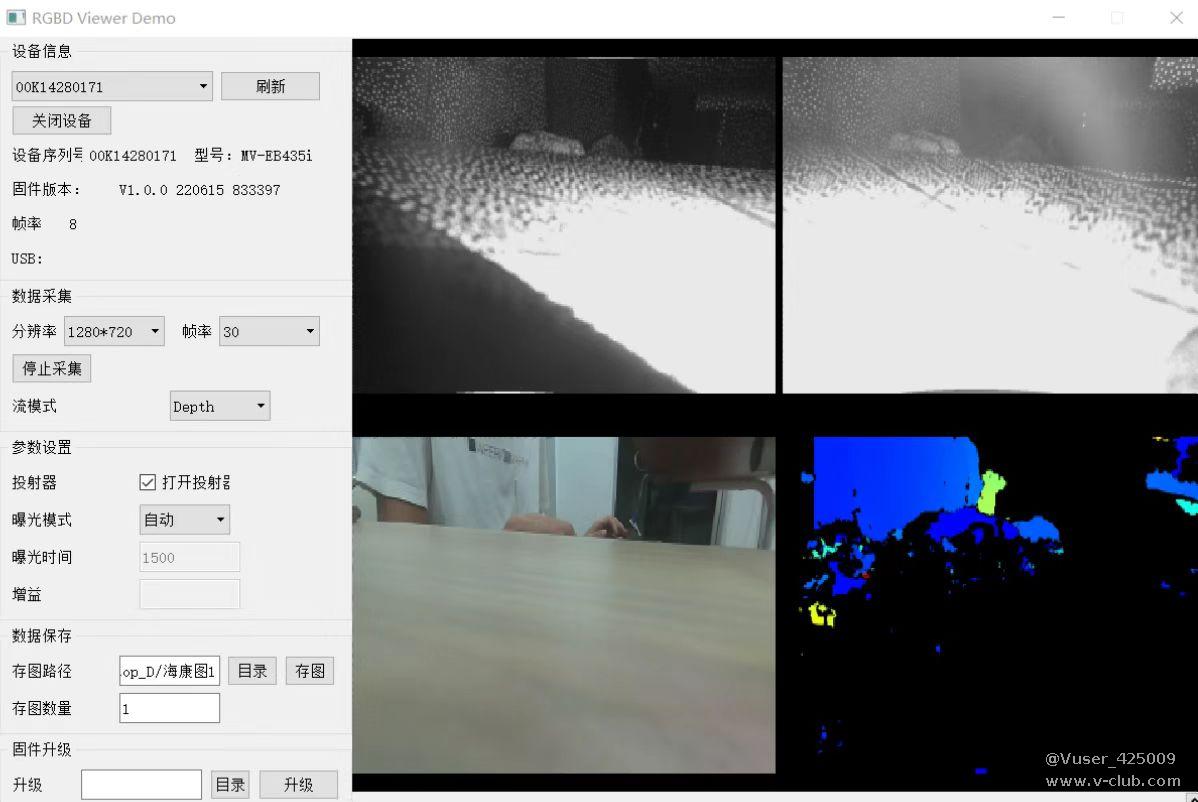
我们打开相机sdk里的qt_view拍摄图片并保存。
4.2.使模型应用于识别
创建detect.py文件,用于加载训练好的模型,导入图像,将图像传入模型里面,输出结果,代码如下:
import torchvision.transforms as transforms
from torchvision import models
import torch.nn as nn
import torch
import os
from PIL import Image
import cv2
import time
import torch.nn.functional as F#用于构造网络模型
os.environ["CUDA_VISIBLE_DEVICES"] = "0"#用gpu训练
val_tf = transforms.Compose([
transforms.Resize(224),
transforms.ToTensor(), transforms.Normalize((0.6477895, 0.6004517, 0.5478299),(0.21435872, 0.2223378, 0.23691148)) ])#图片转化
labels=['其他垃圾_PE塑料袋', '其他垃圾_U型回形针', '其他垃圾_一次性杯子', '其他垃圾_一次性棉签', '其他垃圾_串串竹签', '其他垃圾_便利贴', '其他垃圾_创可贴', '其他垃圾_厨房手套', '其他垃圾_口罩', '其他垃圾_唱片', '其他垃圾_图钉', '其他垃圾_大龙虾头', '其他垃圾_奶茶杯', '其他垃圾_干果壳', '其他垃圾_干燥剂', '其他垃圾_打泡网', '其他垃圾_打火机', '其他垃圾_放大镜', '其他垃圾_毛巾', '其他垃圾_涂改带', '其他垃圾_湿纸巾', '其他垃圾_烟蒂', '其他垃圾_牙刷', '其他垃圾_百洁布', '其他垃圾_眼镜', '其他垃圾_票据', '其他垃圾_空调滤芯', '其他垃圾_笔及笔芯', '其他垃圾_纸巾', '其他垃圾_胶带', '其他垃圾_胶水废包装', '其他垃圾_苍蝇拍', '其他垃圾_茶壶碎片', '其他垃圾_餐盒', '其他垃圾_验孕棒', '其他垃圾_鸡毛掸', '厨余垃圾_八宝粥', '厨余垃圾_冰糖葫芦', '厨余垃圾_咖啡渣', '厨余垃圾_哈密瓜', '厨余垃圾_圣女果', '厨余垃圾_巴旦木', '厨余垃圾_开心果', '厨余垃圾_普通面包', '厨余垃圾_板栗', '厨余垃圾_果冻', '厨余垃圾_核桃', '厨余垃圾_梨', '厨余垃圾_橙子', '厨余垃圾_残渣剩饭', '厨余垃圾_汉堡', '厨余垃圾_火龙果', '厨余垃圾_炸鸡', '厨余垃圾_烤鸡烤鸭', '厨余垃圾_牛肉干', '厨余垃圾_瓜子', '厨余垃圾_甘蔗', '厨余垃圾_生肉', '厨余垃圾_番茄', '厨余垃圾_白菜', '厨余垃圾_白萝卜', '厨余垃圾_粉条', '厨余垃圾_糕点', '厨余垃圾_红豆', '厨余垃圾_肠(火腿)', '厨余垃圾_胡萝卜', '厨余垃圾_花生皮', '厨余垃圾_苹果', '厨余垃圾_茶叶', '厨余垃圾_草莓', '厨余垃圾_荷包蛋', '厨余垃圾_菠萝', '厨余垃圾_菠萝包', '厨余垃圾_菠萝蜜', '厨余垃圾_蒜', '厨余垃圾_薯条', '厨余垃圾_蘑菇', '厨余垃圾_蚕豆', '厨余垃圾_蛋', '厨余垃圾_蛋挞', '厨余垃圾_西瓜皮', '厨余垃圾_贝果', '厨余垃圾_辣椒', '厨余垃圾_陈皮', '厨余垃圾_青菜', '厨余垃圾_饼干', '厨余垃圾_香蕉皮', '厨余垃圾_骨肉相连', '厨余垃圾_鸡翅', '可回收物_乒乓球拍', '可回收物_书', '可回收物_保温杯', '可回收物_保鲜盒', '可回收物_信封', '可回收物_充电头', '可回收物_充电宝', '可回收物_充电线', '可回收物_八宝粥罐', '可回收物_刀', '可回收物_剃须刀片', '可回收物_剪刀', '可回收物_勺子', '可回收物_单肩包手提包', '可回收物_卡', '可回收物_叉子', '可回收物_变形玩具', '可回收物_台历', '可回收物_台灯', '可回收物_吹风机', '可回收物_呼啦圈', '可回收物_地球仪', '可回收物_地铁票', '可回收物_垫子', '可回收物_塑料瓶', '可回收物_塑料盆', '可回收物_奶盒', '可回收物_奶粉罐', '可回收物_奶粉罐铝盖', '可回收物_尺子', '可回收物_帽子', '可回收物_废弃扩声器', '可回收物_手提包', '可回收物_手机', '可回收物_手电筒', '可回收物_手链', '可回收物_打印机墨盒', '可回收物_打气筒', '可回收物_护肤品空瓶', '可回收物_报纸', '可回收物_拖鞋', '可回收物_插线板', '可回收物_搓衣板', '可回收物_收音机', '可回收物_放大镜', '可回收物_易拉罐', '可回收物_暖宝宝', '可回收物_望远镜', '可回收物_木制切菜板', '可回收物_木制玩具', '可回收物_木质梳子', '可回收物_木质锅铲', '可回收物_枕头', '可回收物_档案袋', '可回收物_水杯', '可回收物_泡沫盒子', '可回收物_灯罩', '可回收物_烟灰缸', '可回收物_烧水壶', '可回收物_热水瓶', '可回收物_玩偶', '可回收物_玻璃器皿', '可回收物_玻璃壶', '可回收物_玻璃球', '可回收物_电动剃须刀', '可回收物_电动卷发棒', '可回收物_电动牙刷', '可回收物_电熨斗', '可回收物_电视遥控器', '可回收物_电路板', '可回收物_登机牌', '可回收物_盘子', '可回收物_碗', '可回收物_空气加湿器', '可回收物_空调遥控器', '可回收物_纸牌', '可回收物_纸箱', '可回收物_罐头瓶', '可回收物_网卡', '可回收物_耳套', '可回收物_耳机', '可回收物_耳钉耳环', '可回收物_芭比娃娃', '可回收物_茶叶罐', '可回收物_蛋糕盒', '可回收物_螺丝刀', '可回收物_衣架', '可回收物_袜子', '可回收物_裤子', '可回收物_计算器', '可回收物_订书机', '可回收物_话筒', '可回收物_购物纸袋', '可回收物_路由器', '可回收物_车钥匙', '可回收物_量杯', '可回收物_钉子', '可回收物_钟表', '可回收物_钢丝球', '可回收物_锅', '可回收物_锅盖', '可回收物_键盘', '可回收物_镊子', '可回收物_鞋', '可回收物_餐垫', '可回收物_鼠标', '有害垃圾_LED灯泡', '有害垃圾_保健品瓶', '有害垃圾_口服液瓶', '有害垃圾_指甲油', '有害垃圾_杀虫剂', '有害垃圾_温度计', '有害垃圾_滴眼液瓶', '有害垃圾_玻璃灯管', '有害垃圾_电池', '有害垃圾_电池板', '有害垃圾_碘伏空瓶', '有害垃圾_红花油', '有害垃圾_纽扣电池', '有害垃圾_胶水', '有害垃圾_药品包装', '有害垃圾_药片', '有害垃圾_药膏', '有害垃圾_蓄电池', '有害垃圾_血压计']
def get_out(img,possible):
img_= Image.fromarray(img)#转换格式
img1=val_tf(img_)#图像转化
img1=torch.unsqueeze(img1,0)
img1=img1.cuda()
output = model(img1)#获取输出结果
possible+=F.softmax(output,dim=1)
return possible
def get_label(possible,t1):
pred = possible.data.max(1, keepdim=True)[1]#获取概率最大值索引
possible = round(possible[0][pred].item() * 100, 1)#近似结果
label=labels[pred[0][0].item()]#获得标签
print("花费时间: "+str(time.time()-t1))
print("预测种类: "+label+" "+"概率为: "+str(possible)+"%")
if label[0:4]=="有害垃圾":
print("预测大类为:有害垃圾")
elif label[0:4] == "其他垃圾":
print("预测大类为:其他垃圾")
elif label[0:4] == "可回收物":
print("预测大类为:可回收垃圾")
else:
print("预测大类为:厨余垃圾")
model = models.resnet50(pretrained=False)
fc_inputs = model.fc.in_features
model.fc = nn.Linear(fc_inputs, 214)
model = model.cuda()
# 加载训练好的模型
checkpoint = torch.load( "./model/model_garbage.pth")
model.load_state_dict(checkpoint['state_dict'])
model.eval()
def run():
frame=cv2.imread("./海康图1/1.png")#选择要检测的图片
t1=time.time()
possible = torch.zeros(1, 214)
possible=possible.cuda()
img= frame[:, :, ::-1]#BGR转RGB img=cv2.resize(img,(224,224)#这一步很重要,当图片是jpg格式的时候去掉这行,png要加上,具体原因我也没找到 possible=get_out(img,possible)#输入模型
get_label(possible,t1)#输出标签
if __name__=="__main__":
run()
识别效果如下:


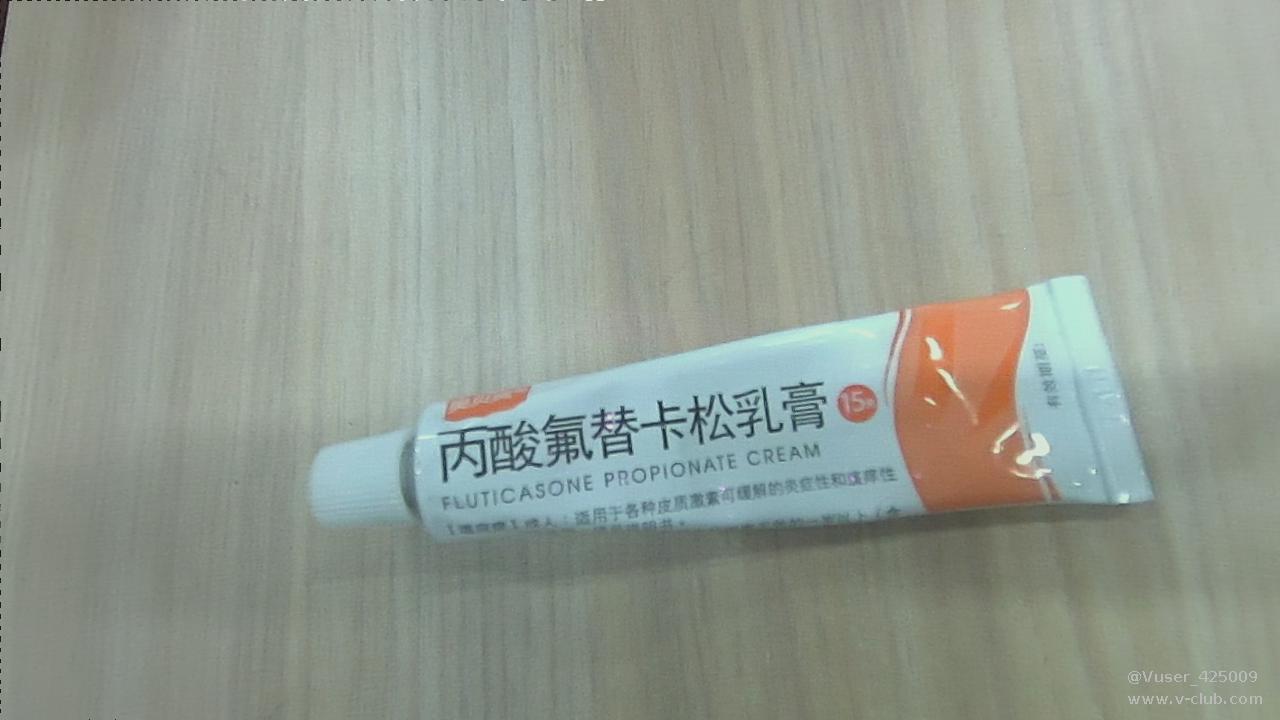





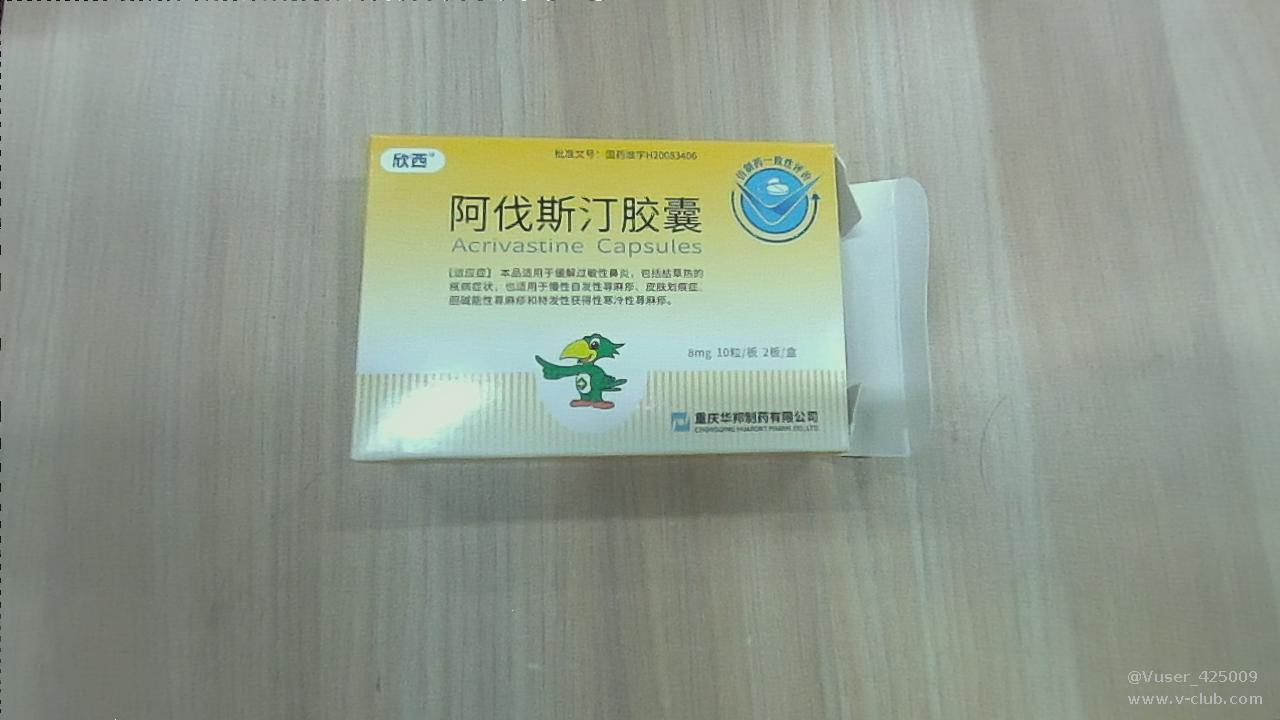









大家看完下面附件的结果就会发现模型对应个别垃圾的分类的识别准确率很低,我们认为可以通过增加数据集数量来解决,反正网上垃圾数据集的数量多的是,下载它们合并起来训练,效果感觉会更好,也可以通过增加模型复杂度来解决问题,比如可以尝试用一下resnet101或resnet152来训练,效果可能会更好。



 探讨海康VisionMasterN点标定的内部原理2024-07-19
探讨海康VisionMasterN点标定的内部原理2024-07-19 关于两起激光方案配置不合理引起的碰撞案例分析2024-07-09
关于两起激光方案配置不合理引起的碰撞案例分析2024-07-09
 浙公网安备 33010802013223号
浙公网安备 33010802013223号