首先抛出一个常见问题:训练样本增大后,模型的预测耗时是否会相应增加?
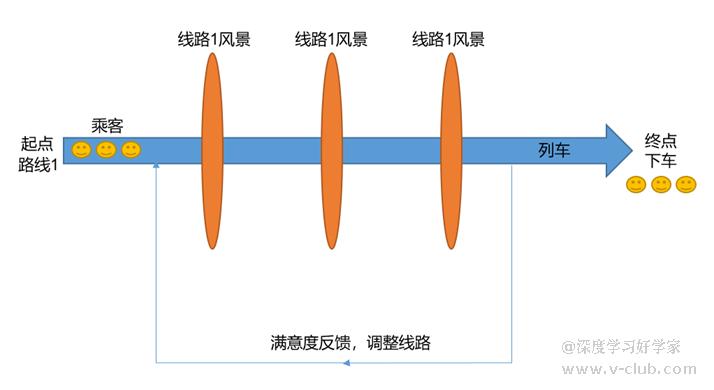
实际上,样本在深度学习网络中只是参与了训练,它们相当于乘客,在一列只有起点和终点两站的高铁上旅行,每经过一个景点就会做拍照记录(卷积,残差,池化,数据交互),在抵达终点前,列车乘务员会反馈乘客的旅途满意度(反向传递),以调整列车路线。到达终点后,乘客下车(此batch迭代完毕),在下一轮次迭代时,再继续坐一趟列车,只不过沿途的风景也发生了变化(权重更新)。
据此,样本数据(乘客)在训练过程中扮演的只是一个系数,做完本职处理工作后,就不在网络中了,所以模型的预测耗时与训练样本量无关,模型的训练耗时则于训练样本量有关。
下面针对目标检测、字符训练和缺陷检测三种算法类型,提供几种降低耗时的方法:
1) 目标检测
参考目标检测训练说明文档的内容,调低patch和模型能力会影响模型在检出低目标占比的表现。

在对小目标做检测时,为保证精度,patch和模型能力还是开到最大,但可以通过调整剪枝的比例来获得精度和耗时的平衡,当前剪枝开放的参数从1-10,映射网络剪枝的百分比从20%-80%,即1代表剪枝20%,10代表剪枝80%。为权衡精度与耗时,实际使用时个人经验最多开到5。


2) 字符训练
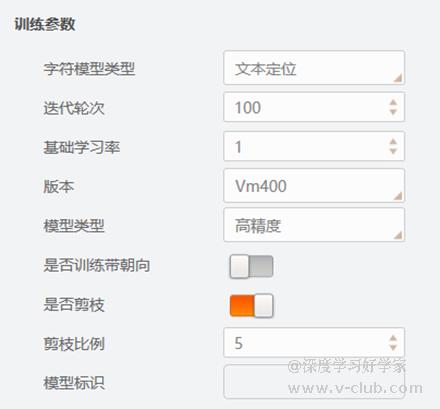
字符训练分为文本定位和文本行识别(拓展),定位模型分为高精度和普通两种,虽然普通可以降低预测耗时,但实测下来,普通模型对字符占比低的数据性能损失较大,容易漏检或定位偏移,建议默认高精度,对于字符角度在-90°~90°的OCR项目,可关闭朝向使能,反之则只能通过箭枝参数降低耗时。
识别模型本身有基础模型,且继承了定位的box,因此耗时很低,耗时降低的幅度极小,不建议使用剪枝功能。
3) 缺陷检测
实际上,缺陷检测耗时的主要来源是网络权重参数的数量,也就是网络构造的复杂度和网络层级的深度,分割任务由于在网络后端需要经过一个上采样的decode操作,则需要考虑像素分辨率带来的额外预测耗时。
- 方法一:从硬件上入手。更换性能更强的GPU,部分30系GPU存在耗时波动大的情况,一般是驱动导致的显存调用问题,目前多张显卡测试下来,466版的驱动比较合适。
- 方法二:从软件方案上入手。如检测区小的情况可以将视野调小(可用于图像分割、异常检测、实例分割),使整体样本的像素减少,提高准确率的同时还能降低预测耗时;

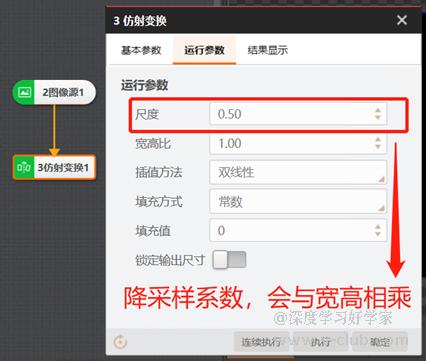
对于一些检出精度不高的场合,可以适当对图片做整体降采样,达到减少预测耗时的目的,比如项目缺陷的检出像素精度为6*6,可以对长宽分辨率做最大两倍的降采样,让缺陷最低在3*3像素,注意这个方法的前提是背景不是非常复杂的情况。降采样可使用VM内自带的仿射变换模块实现;
- 方法三:图像分割可从算法模块上入手。使用快速分割版本(官方提供的补丁包),可极大的降低了DL分割模块的预测耗时,使用方式见这位友人的文章:https://www.v-club.com/home/article/1459。经测试,快速分割多分类模型的耗时相较于图像分割降低了2-3倍,在大多数样本上精度能达到一致,唯一的缺点是无法对各个类别的缺陷概率图分别做处理(见上篇”多分类分割任务下实现指定类别的阈值调整”)








 浙公网安备 33010802013223号
浙公网安备 33010802013223号