操作环境:VisionMaster4.1.0,其他版本个别参数未开放
问题:图像分割、目标检测、字符定位模型,在VM中预测时出现了固定区域的误检情况。
在采用下述解决方法前,需仔细研读对应的训练指导说明,或者可以查阅上篇关于VisionTrain的标注细节,检验标注数据是否合理。
下面本文主要以训练任务划分,列举几种常见的操作问题。
通用解决方法:
- 将误检样本再次添加至训练集,并适当增加迭代轮次(epoch)重新训练,其中:文本行识别开放的是迭代次数(iter)的接口,可以间隔3000适当增加。而图像分割由于内部机制,开放的epoch存在公式系数,因此默认为15,可以间隔5适当增加,如20,25,30。
- 其他训练任务的迭代设置可参照对应的训练指导。
解决方法---按训练任务划分:
图像分割:
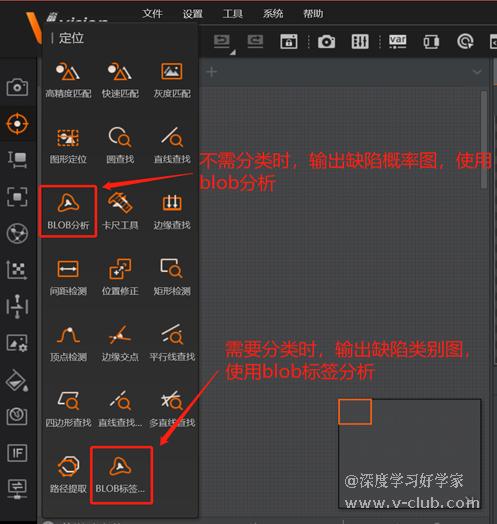
- 对于多分类任务,检查DL图像分割模块是否输出了类别图,后接的blob标签分析模块是否以类别图作为输入源。
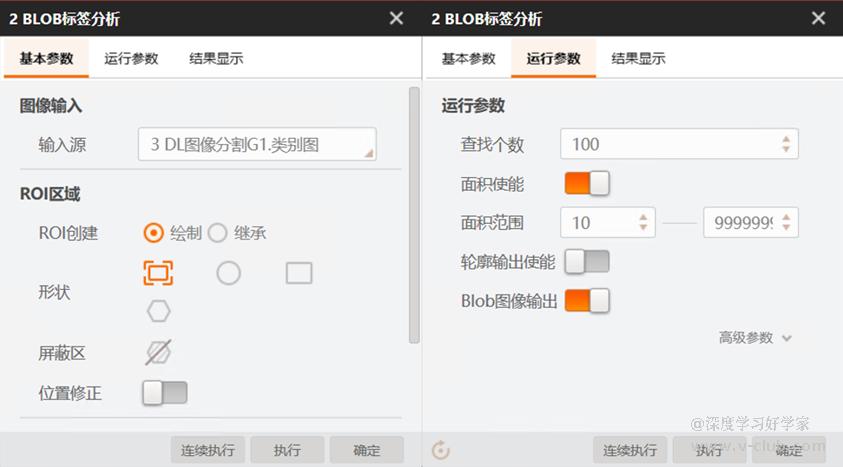
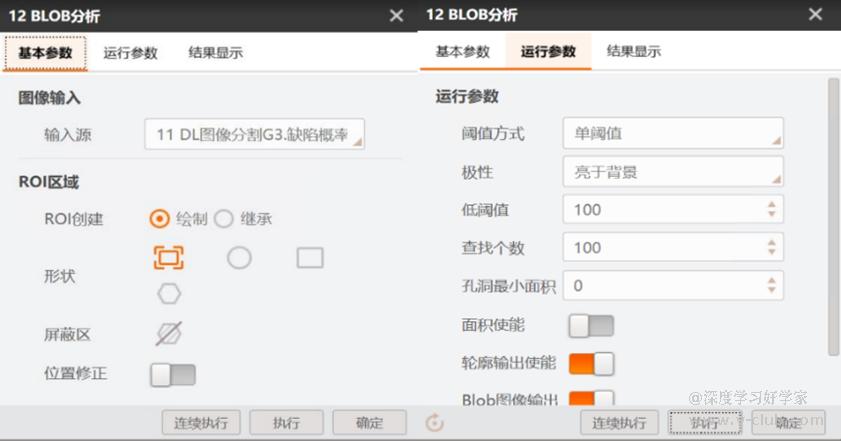
- 对于二分类任务(只定位缺陷的位置,即缺陷有无,在做标注时不用赋予缺陷类别名),检查DL图像分割模块是否只输出了缺陷概率图,后接的blob分析模块是否以缺陷概率图作为输入源,同时在参数设置中极性应是亮于背景。
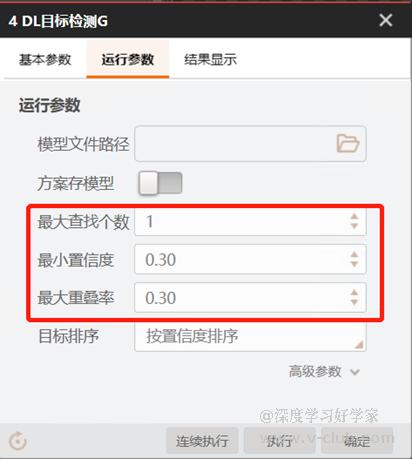
目标检测:
在模块内的参数设置中,调整好查找个数、置信度和重叠率。参数含义为:
- 最大查找个数 :目标检测的最大查找目标个数
- 最小置信度 :目标框的最小得分,小于此数值会被过滤
- 最大重叠率 :两个相同类别目标框之间可重叠的最大比例
注意是否是上述参数的问题,导致某些目标被过滤。
图像分类与图像检索:
- 从样本数据的训练方式以及分类标准上入手,分类和检索由于原理不同,前者更适合类间差距大的场景,后者更适合类内差距小的场景。。
- 图像检索中误识别的样本可注册到gallery对应的类别中。
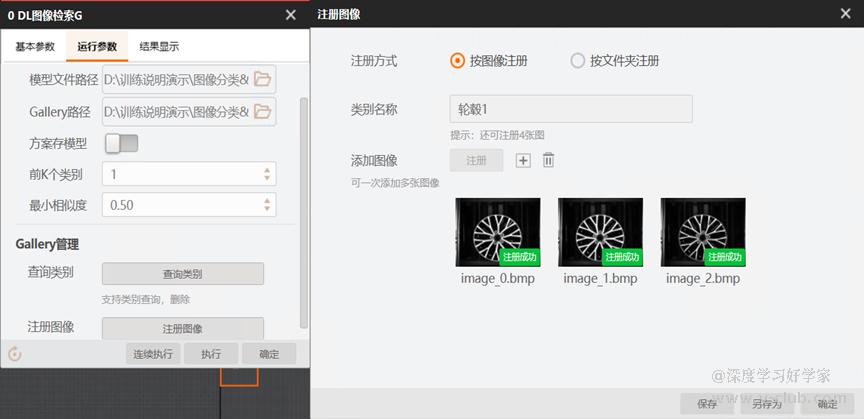
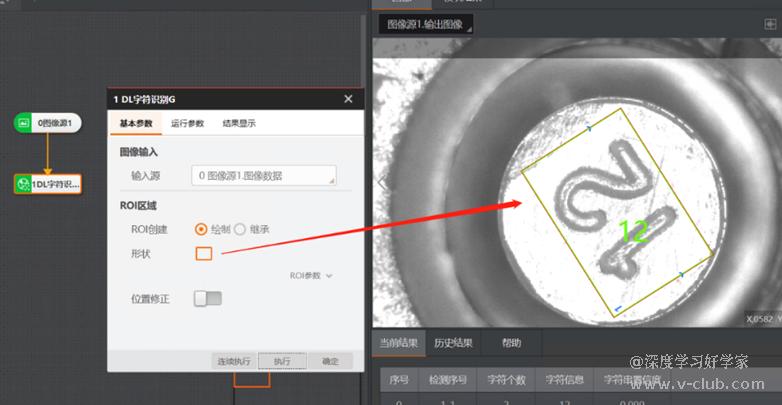
字符定位与字符识别:
- 若字符识别错误,大概率是由于字符定位不准导致,可以在流程中只拖出一个字符识别模块,选取合适的ROI后再观察检出效果。
- 字符行的标注方法详见对应的训练说明文档,包括训练参数的设置。标注的重点在于:对于多字符情况,字符行的左右端需空出半个字符,上下端稍做余留。对于单字符,左右端应空出1个字符,上下稍作余留。
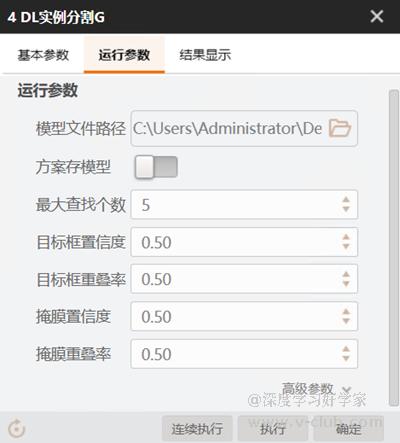
实例分割:
在模块内的参数设置中,调整好查找个数、置信度和重叠率。参数含义为:
- 目标框置信度 :目标框的最小得分值,小于此数值会被过滤
- 目标框重叠率 :两个相同类别的目标框之间可重叠的最大比例
- 掩膜置信度 :掩膜的最小得分值,小于此数值会被过滤
- 掩膜重叠率 :两个掩膜框之间可重叠的最大比例
注意是否是上述参数的问题,导致某些目标被过滤。
异常检测:
- 检查OK样本的规范性,是否存在较大偏移,一般会用在商标logo的缺陷检测。
- 目前VM4.2以及VisionTrain1.4.2推出了无监督功能,算法性能更优于异常检测,针对只存在OK样本的场景下,更推荐使用无监督做测试。







 浙公网安备 33010802013223号
浙公网安备 33010802013223号