








深度学习到底有多奇妙
28篇
- 什么是深度学习?
- 深度学习的前沿研究与应用
- 深度学习和传统算法在缺陷检测应用中的特点
- 深度学习训练工具VisionTrain1.4.1功能更新说明
- 模型优化方法---通用基础篇
- 模型优化方法---VM算法平台预测篇
- 模型优化方法---VisionTrain训练篇
- 模型优化方法---预测耗时篇
- 深度学习小工具之快速图像分割
- 深度学习小工具之标签转化工具
- 深度学习小工具之图像名称、标签文件内容修改工具
- 训练误差与泛化误差的关系
- 训练过程中对于误差值的理解
- 基本图像增强算法对深度学习模型结果的影响
- 使用VM深度学习功能实现模型训练与图像检索功能
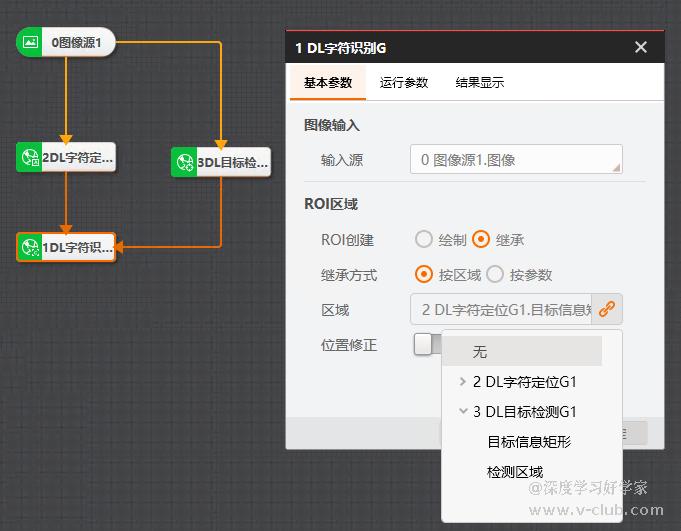
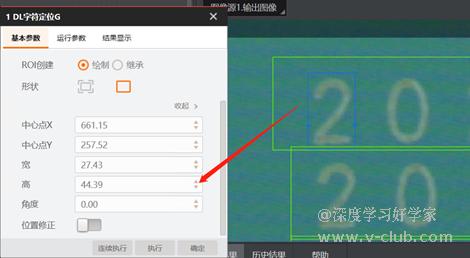
- 智能相机-深度学习OCR训练及优化指南
- 一种提升OCR模型识别率的优化方法
- 根据实际需求找到最优方案-OCR识别篇
- 多分类分割任务下实现指定类别的阈值调整
- 多分类分割任务下的标注问题及解决思路
- 图像分割标注训练经验分享
- 基于VM界面层的多类别缺陷统计方案
- VM深度学习OCR项目经验分享
- 【VM集成开源AI】深度学习算子模块封装
- 深度学习推理耗时波动现象的解决方法
- 【共享学习】关于深度学习显卡推理那些事儿
- VM7100深度学习检测温度传感器焊点,裸针,锡珠,超盘,
- 深度学习缺陷检测项目经验分享





 浙公网安备 33010802013223号
浙公网安备 33010802013223号