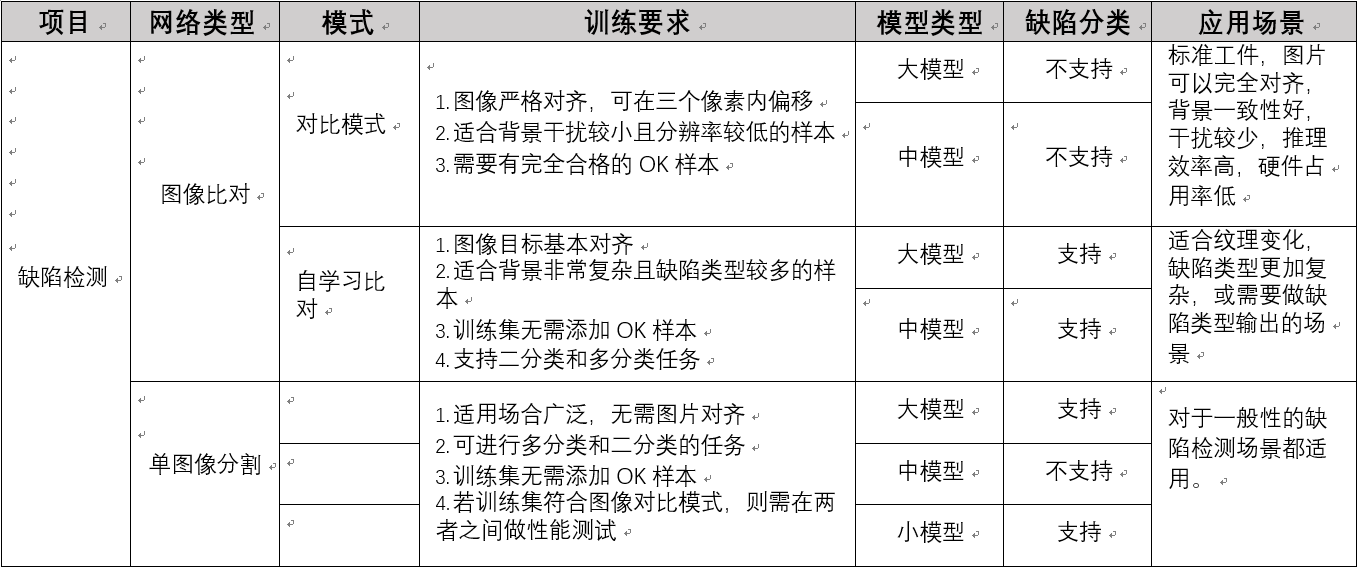
深度学习图像分割,是表面缺陷检测的一种工具,适用于被测物表面的划痕,脏污,裂纹等可标注缺陷的检测,支持多分类缺陷任务,通过深度学习图像分割模块,可输出缺陷概率图及类别图。下图为深度学习图像分割模块的使用场景,可从图中快速浏览各模型的优势:
训练的过程:
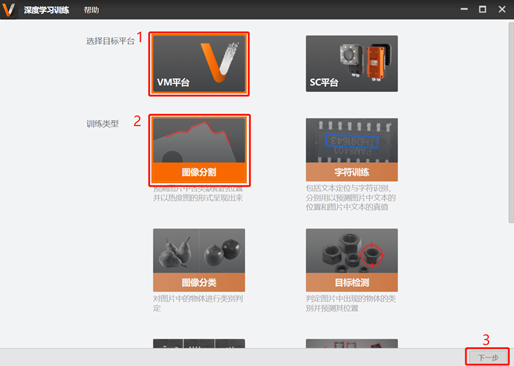
1、打开VisionTrain训练工具
2、选择目标平台->VM平台(VM 平台训练的模型用于VisionMaster软件),选择训练类型->图像分割,点击下一步。
3、进入标定界面
①点击“新建训练集”,创建或选择训练样本,训练样本的绝对路径应当不包含空格(·注:将存在缺陷的样本图片放在一个文件夹中,便于后期增加样本以丰富训练集,训练集图片数量以200张以上为佳。训练样本需具有代表性,尽可能包含各种形态的缺陷类型,新样本的图像分辨率与原样本一致)。
②选中包含有缺陷样本的文件夹,点击确定,将缺陷样本加载至特征标定界面。
③点击画笔工具
或多边形工具
进行缺陷的标定,其中标定时应当尽可能贴近缺陷边缘,否则标定区域过大,使非缺陷特征数据进入深度学习网络,导致模型学习效果不佳。
④当选择“单图像分割”进行模型训练时,如训练集中存在多个缺陷类别,可以在标定缺陷区域后,选择“操作”栏下的”缺陷类别”中填入数字或者中文,用来指出该缺陷的类别归属。一般默认标注的区域为缺陷特征,即在”操作”下方的”严重程度中”默认为”缺陷”,而“忽略”则表示某些与缺陷非常接近的特征容易误判,需要排除忽略掉。

⑤当选择“图像对比”进行模型训练时,如选择模板类型为“自学习“,无需要加载额外的 OK 样本,只需按照步骤④一样标注缺陷,如步骤④图中所示。
⑥当选择“图像对比”进行模型训练时,如选择模板类型为“对比“,由于该类型不支持多分类任务,因此,对缺陷特征进行标注后无需定义缺陷类别,同时在训练集中额外加载一张完全合格的图像并标记为 OK, 条件允许情况下建议 OK 样本量为三张,如下两张图所示。
⑦缺陷标定注意事项如下:
(1)目前,单图像分割小、大模板与图像对比的”自学习”模板可以实现缺陷检测的多分类任务,这两种训练类无需添加OK 样本,在标注时需要对每个缺陷配置好缺陷类别。而图像对比的”对比”模板与单图像分割中模板,需要添加OK样本,且不能在标注时配置缺陷的类别。
(2)在标注时应尽量逐像素标定,并贴近缺陷的形状和方向,减少非缺陷特征的干扰。
需避免下图的标记情况:

包含大量的背景信息

出现漏标的情况

同时将其他缺陷特征也包含进来
训练参数说明
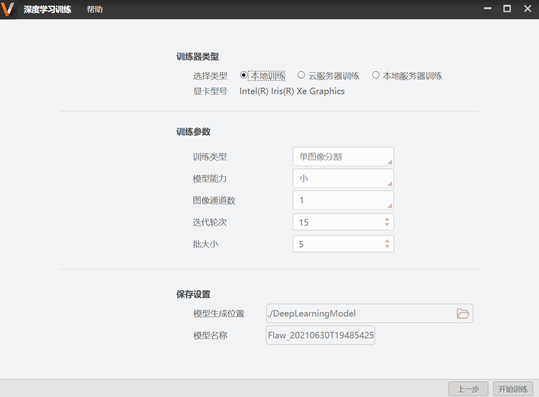
图像分割模式:
选择类型:本地训练-依赖本机显卡训练;云服务器训练-使用萤石云进行训练;本地服务器训练-在本地架设的服务器上训练。
模型能力:共有小、中、大三种模型,其中小模型与大模型都能应对复杂背景下的模型训练, 小模型的训练和检测运行效率高,大模型的检出效果更加精细。另外,在缺陷形态种类较少或样本量较少的情况下可选择小模型,反之则选择大模型。而中模型应尽量选择在低复杂背景下的模型训练, 能够达到训练效率、检测运行效率和检出效果的良好平衡。.
图像通道数:图像源是黑白的选择1通道,图像源是彩色的选择3通道。
迭代轮次:整个训练集参加训练的次数(即epoch),默认为15,该值为一个固定的乘法系数, 在算法中已经可以根据训练集的大小来调整最优的迭代轮次,一般不建议调整该系数。
批大小:迭代一次时输入训练网络的样本量(即batch),默认为5,一般不建议调整该系数。
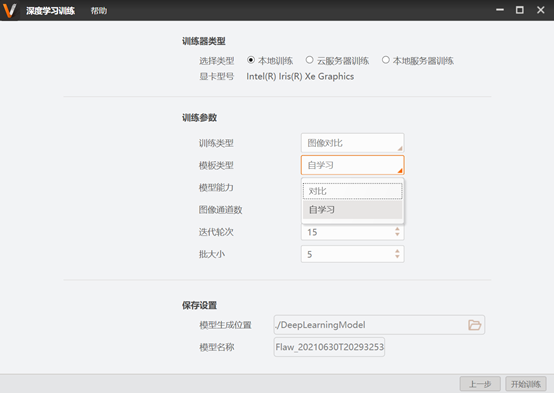
图像比对模式:
选择类型:本地训练-依赖本机显卡训练;云服务器训练-使用萤石云进行训练;本地服务器训练-在本地架设的服务器上训练。
模板类型:有对比和自学习两种模板类型。对比模板类型要求训练样本的图像背景干扰较少, 且目标物体是严格对齐的(目标位移在 3 个像素之内)。自学习模板类型要求较为宽泛,保持目标物体是基本对齐的即可,同时在复杂背景下表现较优,比如变化的文字、二维码等。自学习模板类型在样本量适中的情况下,应当与单图像分割模型进行实验对比,测试处当前样本条件下最优的模型选择。
模型能力:共有中模型和大模型,中模型比大模型的检测运行效率更快,而大模型比中模型的检出精度更高。
图像通道数:图像源是黑白的选择1通道,图像源是彩色的选择3通道。
迭代轮次:整个训练集参加训练的次数(即epoch),默认为15,该值为一个固定的乘法系数, 在算法中已经可以根据训练集的大小来调整最优的迭代轮次,一般不建议调整该系数。
批大小:迭代一次时输入训练网络的样本量(即batch),默认为5,一般不建议调整该系数。
训练过程:
若不设模型保存路径,则将会保存在默认位置,即\VisionTrain1.4.0\Applications\DeepLearningMode 下。确定好模型名称后点击开始训练,随着迭代次数的增加,训练误差会越来越小,最后趋于平缓。当训练完成后点击结束训练,在指定的文件夹位置会生成一个.bin文件,该文件则是深度学习网络训练后得到的模型文件。
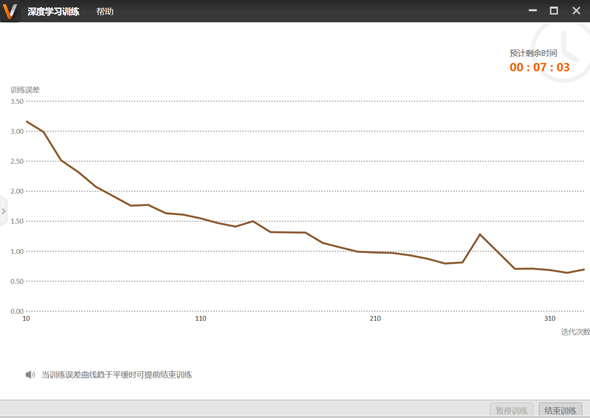
通过以上步骤,就可以得到训练的模型,然后利用VM的图像分割工具进行测试验证。









 浙公网安备 33010802013223号
浙公网安备 33010802013223号